Introduction
HDFS stores file in multiple equal large size block e.g. 64 MB, 128 MB etc. and MapReduce framework access and process these files in distributed environment.
The MapReduce framework works on key-value pairs, it has two key part Mapper and Reducer.Map Reducers read file and split and pass to Mapper. Mapper set the input as key-value pairs and pass to the intermediate for sorting and shuffling. Reducer takes the key and list of value, process and writes to the disk.
Flow:
Job Client submit job to Job Tracker and simultaneously copy the Mapper, Reducer and config package to HDFS. Job Tracker lookup to NameNode to identify the data information. Job Tracker create execution plan and executes TaskTracker. JobTracker also coordinate the Task Tracker and keep maintain the status of TaskTracker.
Task Tracker, which is placed locally to data node, identifies the available slots in the local node if it is not available in local it goes to rack or cross racks. Task Tracker report progress to Job Tracker via heartbeats.
Job Tracker first allowed executing the entire Mapper task once all the mapper get complete it will start executing Reducer task. Job Tracker also reschedule the task if fails. Once TaskTracker finish it will update the status to Job Tracker.
Below diagram depicts high-level MapReduce process flow:

Map Reduce process keep the TaskTracker locally and it execute the job where data reside which optimize the network latency.
Below diagram depicts how map reduce works:
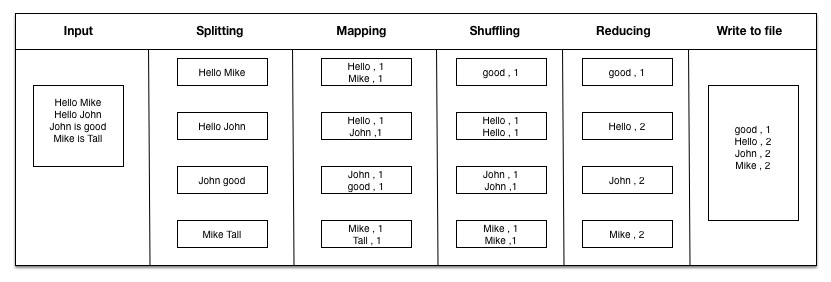
TaskTracker split the file and pass to mapper and mapper converts it into <Key, Value> map. As per above example it uses TextInputFormat to split input file into lines.
Mapper split the line into word and uses Text to store word as key and IntWritable to store 1 as count value. Mapper passes map to OutputCollector, which intern shuffle and sort the map. Combiner is optional which optimize the reducer on node level. Here we are using Reducer as Combiner to combine the output to a single file.
We will try to explain the code based on simple Word Count example whereas MapReduce will read text file’s word and write to the output file as word number of occurrence in sorted order.
Hadoop Setup:
We can refer to the link to how to setup embedded Hadoop in local system.
Project Dependency
Create a maven based Java project and add the below Hadoop core dependency in POM. In this application I am using Hadoop 1.x version.
<dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-core</artifactId> <version>1.2.1</version> </dependency> </dependencies>
Mapper
Mapper read the line and set the word as key with count 1 as value
public static class SampleMapper extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable count = new IntWritable(1);
private Text text = new Text();
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException {
String line = value.toString ();
StringTokenizer tokenizer = new StringTokenizer (line);
while (tokenizer.hasMoreTokens()) {
text.set(tokenizer.nextToken());
Output.collect(text, count);
}
}
}
Mapper set the key-value to OutputCollector, which push data to intermediate for sorting and shuffling. Key-value should be searlized and implement comparable interface to write on network and sort the output simultaneously.
Here org.apache.hadoop.io.Text class as key, which provides methods to searlized, and compare texts at byte level. The value IntWritable again searlized as it implements writable interface and support sorting as it implements WritableComparable interface.
Reducer:
Output from Sort/Shuffle is input of Reducer. Reducer process key-value and push to the disk by using OutputCollector.
We can also use reducer as combiner, which combines the reducers’ output across the network.
public static class SampleReducer extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output,
Reporter reporter) throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
JobConf
For running the MapReduce we have to set the Mapper, Reducers and other property in JobConf. JobConf is the main configuration class, which configure MapReduce parameters such as Mapper, Reducer, Combiner, InputFormat, OutputFormat, and Comparator etc.
public static void main(String[] args) throws Exception {
String inputPath=args[0];
String outputPath=args[1];
JobConf conf = new JobConf(SampleMapReduce.class);
conf.setJobName("SampleMapReduce");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(SampleMapper.class);
conf.setCombinerClass(SampleReducer.class);
conf.setReducerClass(SampleReducer.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(inputPath));
FileOutputFormat.setOutputPath(conf, new Path(outputPath));
JobClient.runJob(conf);
}
As per above code, framework will execute the map-reduce job as described in JobConf.
Running
To run the MapReduce program is quite straight forward, what we need to do package the java application in JAR say samplMapReduce.jar and run as below in command line
hadoop jar samplMapReduce.jar.jar org.techmytalk.mapreducesample. SampleMapReduce /input folder in HDFS /output folder in HDFS
Summary:
In this article I tried to explain basic understanding on MapReduce.Use download link to download full source code.
Reference
Hadoop Essence: The Beginner’s Guide to Hadoop & Hive

Reblogged this on HadoopEssentials.