A Collection represents a group of objects known as elements. Collection framework is basically group of interface with some specific implementation to manage elements of collection. Below diagram depicts the key interfaces on Collection framework: 
Above diagram represent key interfaces and implementation of collection framework. Collection also consists default abstract implementation to for generic implementation.
Following are the brief description on Collection framework:
- Iterable defines the contract that a class has to fulfill for its instances, how they iterate on collection.
- Collection interface contains the base functionalities required for any collection other than a map. A collection has no special order and doesn’t reject duplicate
- Set interface unique feature is that it does not accept duplicate elements but could not give guarantee on sorted record.
- Sorted Set interface extends Set interface automatically sorts its elements and returns them in order.
- HashSet: This is a set, so it doesn’t permit duplicate and it uses hashing for storage. This class implements the Set interface, backed by HashMap instance. It makes no guarantees as to the iteration order of the set; in particular, it does not guarantee that the order will remain constant over time. This class permits the null element. HashSet internally used HashMap to store values as key
- Queue interface follow FIFO policies that means the element insert first come, out first from the queue.
- Deque interface extends Queue, which allow elements to add/removed at both head and tail.
- List is a collection in which order is significant, accommodating duplicate elements and null value elements.
- Linked list: This is an implementation of a list, based on linked-list storage. Linked list allows add or remove element at any location. Size can grow arbitrary. LinkedList is significantly slower by index than array. Ordering very easily.
- Vector: This class implements a list using an array internally for storage. The array is dynamically reallocated as necessary, as the number of items in the vector grows. Vector is class in the old way of list collection whereas its operation or synchronize however ArrayList doesn’t support synchronize.
- Stack—It behave as LIFO means element which goes last will come out first.
Difference between ArrayList and LinkedList LinkedList and ArrayList both implement List Interface but how they work internally make difference . Main difference between ArrayList and LinkedList is that ArrayList is implemented using re sizable array while LinkedList is implemented using doubly LinkedList
- Since Array is an index based data-structure searching or getting element from Array with index is pretty fast. Array provides O(1) performance for get(index) method but remove is costly in ArrayList as you need to rearrange all elements. On the Other hand LinkedList doesn’t provide Random or index based access and you need to iterate over linked list to retrieve any element which is of order O(n)
- Insertions are easy and fast (specially in middle) in LinkedList as compared to ArrayList because there is no risk of resizing array and copying content to new array if array gets full which makes adding into ArrayList of O(n) in worst case, while adding is O(1) operation in LinkedList in Java.
- ArrayList also needs to update its index if you insert something anywhere except at the end of array
- Removal is like insertions better in LinkedList than ArrayList.
- LinkedList has more memory overhead than ArrayList because in ArrayList each index only holds actual object (data) but in case of LinkedList each node holds both data and address of next and previous node.
Map Map and SortedMap form a separate hierarchy and not connected with Collection interface. But still, they are treated as part of collections framework. It is done so to get interoperability with collections and legacy classes. Below diagram depicts the key interfaces on Map: 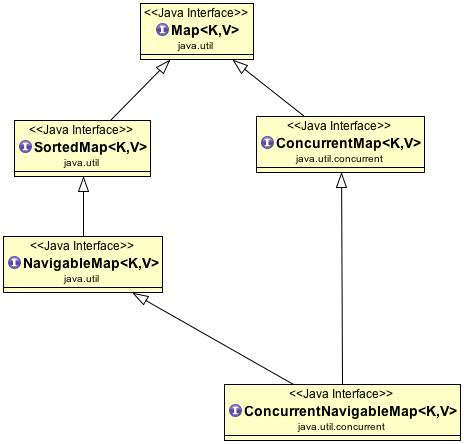 It uses key-value associations to store and retrieve elements. ConcurrentMap provides support for concurrent access, SortedMap guarantees to return its values in ascending key order,NavigableMap extends SortedMap to find the closest matches to a target element. Following are the brief description on Collection framework:
It uses key-value associations to store and retrieve elements. ConcurrentMap provides support for concurrent access, SortedMap guarantees to return its values in ascending key order,NavigableMap extends SortedMap to find the closest matches to a target element. Following are the brief description on Collection framework:
- Map: adds the elements in key/value pairs. Duplicate keys are not allowed, but duplicate values are allowed. One key can map one value only.
- TreeMap: This class provides an ordered set, using a tree for storage. It sort the elements either using externally supplied comparator or natural order by compareTo () method. It passes Comparator on constructor for sorting however if you don’t pass constructor it does natural sorting.
- TreeMap implements SortedMap Tree: Allows easy addition and insertion and arbitrary growth Insists on a means of ordering more efficient searching than either an array or linked list HashTable:
Difference between Collection and array The key difference between collection and array is that collection API is a mechanism for manipulating object references whereas arrays are capable of storing primitives or references. Array storage tends to be fast to access, but difficult to search, insert in middle, modification, increasing the size. But it is good for data’s that are ordered, do not change often, not search much
Hashing: Unique key associated with each data type, which in-terns provides efficient searching. Hashing may be inappropriate for small data sets, since it has overhead associated with calculating the hash values and manipulating the more complex data structure associated with type of storage. Without a sufficiently large number of elements that would not justify the operational cost Collection Sort SortedSet and SortedMap interfaces maintain sorted order. All elements inserted into a sorted set must implement the Comparable interface (or be accepted by the specified comparator). Example
private TreeMap<Ktr> collection = new TreeMap<Ktr>(); //Ktr pass Comparator or implement comparable private SortedSet<Kr> collection=new SortedSet<Ktr>();; //Ktr pass Comparator or implements comparable
Set and Map could also provide ordering of their elements by using Comparable (Natural Order) or Comparator (external comparator) Java.util. Arrays and java.util. Collections are two utility classes which might be used to order the collection as below
Arrays: Arrays sorts array of objects by two ways:
- It sorts the arrays of objects by the specific comparator as below
public static <T> void sort(T[] a, Comparator<? super T> c)
- It sorts the arrays of objects whereas each object of array should implements Comparable interface.
public static void sort(Object[] a)
Difference between Comparable and Comparator
- Comparator in Java is defined in java.util package while Comparable interface in Java is defined in java.lang package.
- Comparator interface in Java has method public int compare (Object o1, Object o2) which returns a negative integer, zero, or a positive integer, as the first argument is less than, equal to, or greater than the second. While Comparable interface has method public int compareTo (Object o), which returns a negative integer, zero, or a positive integer, as this object is less than, equal to, or greater than the specified object.
- Comparable in Java is used to implement natural ordering of object. In Java API String, Date and wrapper classes implements Comparable interface. Its always-good practice to override compareTo () for value objects.
- If any class implement Comparable interface in Java then collection of that object either List or Array can be sorted by using Collections. Sort () or Arrays. Sort () method and object will be sorted based on there natural order defined by CompareTo method.
- Objects which implement Comparable in Java can be used as keys in a SortedMap like TreeMap or elements in a SortedSet for example Tree Set, without specifying any Comparator
When to Use Comparable and Comparator
- If there is a natural or default way of sorting and Object already exist during development of Class than use Comparable. This is intuitive and you given the class name people should be able to guess it correctly like Strings are sorted chronically, Employee can be sorted by there Id etc. On the other hand if an Object can be sorted on multiple ways and client is specifying on which parameter sorting should take place than use Comparator interface. e.g. Employee can again be sorted on name, salary or department and clients needs an API to do that. Comparator implementation can sort out this problem.
- Some time you write code to sort object of a class for which you are not the original author, or you don’t have access to code. In these cases you cannot implement Comparable and Comparator is only way to sort those objects.
Comparable and Comparator The “Comparable” allows itself to compare with another similar object (i.e. A class that implements Comparable becomes an object to be compared with). The method compareTo () is specified in the interface. Comparator interface The Comparator is used to compare two different objects. The following method is specified in the Comparator interface. Iterator and Iterable Iterable interface is the part of java.lang which is extended by Collection interface. It keeps only one method iterator () which return Iterator over a set of elements of type T. Implementing this interface allows an object to be the target of the “foreach” statement.
public interface Iterable<T>
{
Iterator<T> iterator();
}
Iterator replace legacy Enumeration to traverse the elements of Collection. Iterator provides remove method to remove elements from underlying collection, which was not available in old Enumeration.
public interface Iterator<E>
{
boolean hasNext();
E next();
void remove();
}
Since Collection extends Iterable therefore it could be iterated using an Iterator and can be used in for each loop. The iterator is the actual object that will iterate through the collection An iterator is stateful hence if you call Iterable.iterator () twice you’ll get independent iterator. In particular, you could have several iterators working over the same original Iterable at the same time The java.util.ListIterator is an iterator for lists that allows the programmer to traverse the list in either direction (i.e. forward and or backward) and modify (remove) the list during iteration. ConcurrentModificationException using an iterator The java.util Collection classes are fail-fast, which means that if one thread changes a collection while another thread is traversing it through with an iterator the iterator.hasNext () or iterator.next () call will throw ConcurrentModificationException. We can avoid by converting list to Array and iterate on the array or we can lock the entire list while iterating but these approach adversely affects scalability of your application if it is highly concurrent. JDK1.5 and above provide ConcurrentHashMap and CopyOnWriteArrayList classes, which provide much better scalability and the iterator returned by ConcurrentHashMap. Iterator () will not throw ConcurrencModificationException while preserving thread-safety.
Benefits of the Java Collections Framework Collections framework provides flexibility, performance, robustness and Polymorphic algorithms (sorting, shuffling, reversing, binary search etc.).
Custom Defined Key While creating key object for HashMap or HashTable we should always override the equals () and hashCode () methods from the Object class. The default implementation of the equals () and hashcode (), which are inherited from the java.lang.Object uses an object instance’s memory location. This may cause problems if you want to compare the object entities for example objects which having same value return false if we don’t override equal () and hashCode () method. We also override toString () method can be overridden to provide a proper string representation of your object. What are the primary considerations when implementing a user defined key?
- If a class overrides equals (), it must override hashCode ().
- If 2 objects are equal, then their hashCode values must be equal as well.
- If a field is not used in equals (), then it must not be used in hashCode ().
- If it is accessed often, hashCode () is a candidate for caching to enhance performance.
- It is a best practice to implement the user defined key class as an immutable object.
Note:
- Use ArrayList, HashMap etc. as opposed to Vector, Hashtable etc., where possible to avoid any synchronization overhead.
- If multiple threads concurrently access a collection and at least one of the threads either adds or deletes an entry into the collection, then the collection must be externally synchronized. This is achieved by:
- Map myMap = Collections.synchronizedMap (myMap); //conditional thread-safety
- List myList = Collections.synchronizedList (myList); //conditional thread-safety
- Use java.util.concurrent package for J2SE 5.0 ConcurrentModificationException
- Set the initial capacity of a collection appropriately (e.g. ArrayList, HashMap etc). This is because Collection classes like ArrayList, HashMap etc. must grow periodically to accommodate new elements. But if you have a very large array, and you know the size in advance then you can speed things up by setting the initial size appropriately.
- Program in terms of interface not implementation: For example you might decide a LinkedList is the best choice for some application, but then later decide ArrayList might be a better choice for performance reason. Use:
List list = new ArrayList (100); Instead of: ArrayList list = new ArrayList ();
- Return zero length collections or arrays as opposed to returning null: Returning null instead of zero length collection (use Collections.EMPTY_SET, Collections.EMPTY_LIST, Collections.EMPTY_MAP) is more error prone, since the programmer writing the calling method might forget to handle a return value of null.
- Immutable objects should be used as keys for the HashMap: Generally you use a java.lang.Integer or a java.lang.String class as the key, which are immutable Java objects. If you define your own key class then it is a best practice to make the key class an immutable object (i.e. do not provide any setXXX () methods etc.). If a programmer wants to insert a new key then he/she will always have to instantiate a new object (i.e. cannot mutate the existing key because immutable key object class has no setter methods).
- Encapsulate collections: In general collections are not immutable objects. So care should be taken not to unintentionally expose the collection fields to the caller.
Concurrent in JDK5 The “java.util.concurrent” package provides thread safe collections such as ConcurrentHashMap, CopyOnWriteArrayList which can use on multi thread environment. CopyOnWriteArrayList, CopyOnWriteArraySet allows to access and change by multiple threads in thread safe manner. It behaves like List or Set except that when the list modified, it create new array and old array get discarded. It will not throw concurrent modification exception if modified during iteration. CopyOnWriteArrayList/ CopyOnWriteArraySet object’s array is immutable and therefore it provide thread safe without requiring either synchronization or clone ().
CopyOnWriteArrayList A thread-safe variant of ArrayList in which all mutative operations add, set, and so on) are implemented by making a fresh copy of the underlying array. This is ordinarily too costly, but may be more efficient than alternatives when traversal operations vastly outnumber mutations, and is useful when you cannot or don’t want to synchronize traversals, yet need to preclude interference among concurrent threads. The “snapshot” style iterator method uses a reference to the state of the array at the point that the iterator was created. This array never changes during the lifetime of the iterator, so interference is impossible and the iterator is guaranteed not to throw ConcurrentModificationException. The iterator will not reflect additions, removals, or changes to the list since the iterator was created. Element-changing operations on iterators themselves (remove>, set, and add) are not supported. These methods throw UnsupportedOperationException. CopyOnWriteArrayList is expensive compare to normal ArrayList because it copy whole Array in each update but it is very efficient on multithread operation. Note: It throws an UsupportedOperationException if you tried to sort. You should only use this read when you are doing upwards of 90+% reads If you look at the underlying array reference you’ll see it’s marked as volatile. When a write operation occurs (such as in the above extract) this volatile reference is only updated in the final statement via setArray. Up until this point any read operations will return elements from the old copy of the array. The important point is that the array update is an atomic operation and hence reads will always see the array in a consistent state.
ConcurrentHashMap: Similar to CopyOnWriteArrayList, ConcurrentHashMap is thread safe collection, which could be read by unlimited number of thread and write by limited number of thread at a time. It provides an implementation of Map that is thread safe. Multiple threads can read from and write to it without the chance of receiving out-of-date or corrupted data. ConcurrentHashMap provides its own synchronization, so you do not have to synchronize accesses to it explicitly. Another feature of ConcurrentHashMap is that it provides the putIfAbsent method, which will atomically add a mapping if the specified key does not exist. However, even though all operations are thread-safe, retrieval operations do not entail locking, and there is not any support for locking the entire table in a way that prevents all access. Retrieval operations (including get) generally do not block, so may overlap with update operations (including put and remove) hence retrievals reflect the results of the most recently completed update operations holding upon their onset. Iterators and Enumerations return elements reflecting the state of the hash table at some point. They do not throw ConcurrentModificationException. However, iterators are designed to use by only one thread at a time. ConcurrentHashMap subdivide the table into multiple Segments and each Segment created only when it needed. Segment’s table uses volatile to access its elements. These subdivided/-partitioned segments try to permit limited number of concurrent updates without overlap. It does not allow null to be used as a key or value. .The idea is that the number of Segments should equal the number of concurrent writer threads that you normally see. And, the default value for concurrency Level is 16! In ConcurrentHashMap, the lock is applied to a segment instead of an entire Map. Each segment manages its own internal hash table. The lock is applied only for update operations. Collections.synchronizedMap (Map) synchronizes the entire map References: http://docs.oracle.com/javase/7/docs/api/

Java Collection framework is a very popular framework of Java which provides a strong architecture to store or easily control the group of objects. For the purpose of better understanding.